业务场景
我在写爬虫的时候就经常喜欢造轮子,不太喜欢用框架写。所以一般用的就是requests+解析库+mongodb。写起来的话灵活性非常强。
这里介绍一种爬虫的场景,就是我们要爬去的数据量是已知的,或者页面数目是已知的,先爬取前10页,或者先更新后10页没有区别。
这里假如说我想爬链家北京房价,我可以先跑一遍最基本的链接找出来,可能东城区有10万页要更新(肯定没有这么多举例子),海淀区有8万页,西城区有12万页,玄武区5万页,等等。。。。,假如说加起来是100万页。
然后这个时候我可能有10台服务器,如何将这100页分配给10台或者不同台的服务器呢,这里其实我想到的最简单的一个方法就是通过一个分类器。
一行代码怎么加
这里假如这100万页放在mongodb的lianjia数据库的tasks表里面,我们可以通过以下的方式完成一个分布式爬取功能。
1 | import pymongo |
这里最主要的是通过这个get_class_num函数的实现,它接受一个字符串,并把这个字符串映射成一个唯一的一个数字。
一个简单的分类函数的实现
说到映射成唯一的一个数字,那么就可以想到md5了。我这里用的办法也就是md5。这里一个简单的方案实现如下:
1 | import hashlib |
上面的代码也就是先把字符串转成md5串,然后取md5串的最后一个字母的ascii码作为分类的id。然后就可以通过取模的方法分类了。
分成2类
我们这里测试一下分成2类的分布如何,我们随机生成10万个任务,看看能不能将这10万个分成两半。
1 | import random |
运行之后可以看到两个类别的数量差100多,基本不差什么。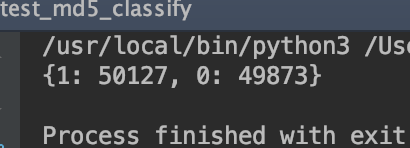
分成3类
然后再测一下三类的。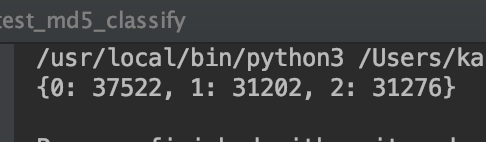
这里一个是3.75万,两个是3.12万。可以发现差了很多。
分类器的完善
这里其实是因为我们的id分布不均匀的缘故。md5输出的结果是26个小写字母+10个数字,一共36种字母。数字的ascii码从48到57,小写字母的ascii码从97到122。除了二分类,其实很难保证分配很均匀。
这里其实有一个简单的方法,就是多加几个字母,我们不只是取最后面一个字母的ascii码,而是把最后面好几个的ascii码加起来。
1 | def get_class_num(_str): |
然后在测试一下三个类的。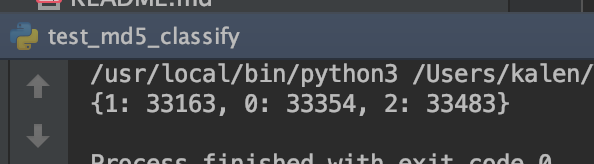
这里就好了,我们再测一下7个类。
看着也很均匀。
我测了一下五个字符相加20个类都很okay,不过再多的比如说100个类这种肯定是不行。如果类别特别多,可以再多加几个字符的ascii码提高随机性。
添加id重置服务
以上的办法虽然解决了一定的分布式爬虫问题。但是实际中,服务器处理任务的能力不一样,每个任务的难度也不一样。还是会出现分配不均匀的情况。
这里可以添加一个id重置服务,我们有一个进程每隔一段时间,比如说1天或者几个小时,生成一个随机字符串,然后通过get_class_num(task["id"] + random_string)的方式,重新设置一遍id。
这样可以保证不会出现一直空机器的情况。
自我总结
爬虫的设计除了爬取之后,我觉得就是处理任务分配的逻辑,每个任务都十分的隔离。
这种方法可以保证没有额外的代码编写的情况下,完成相对高效的分布式爬虫。主要还是懒得写别的代码,所以想出了这种方法把。